
We introduced a new 9-DoF benchmark on 20 novel categories apart from 9 categories available in Scan2CAD called SUN2CAD. The dataset is provided in this link.
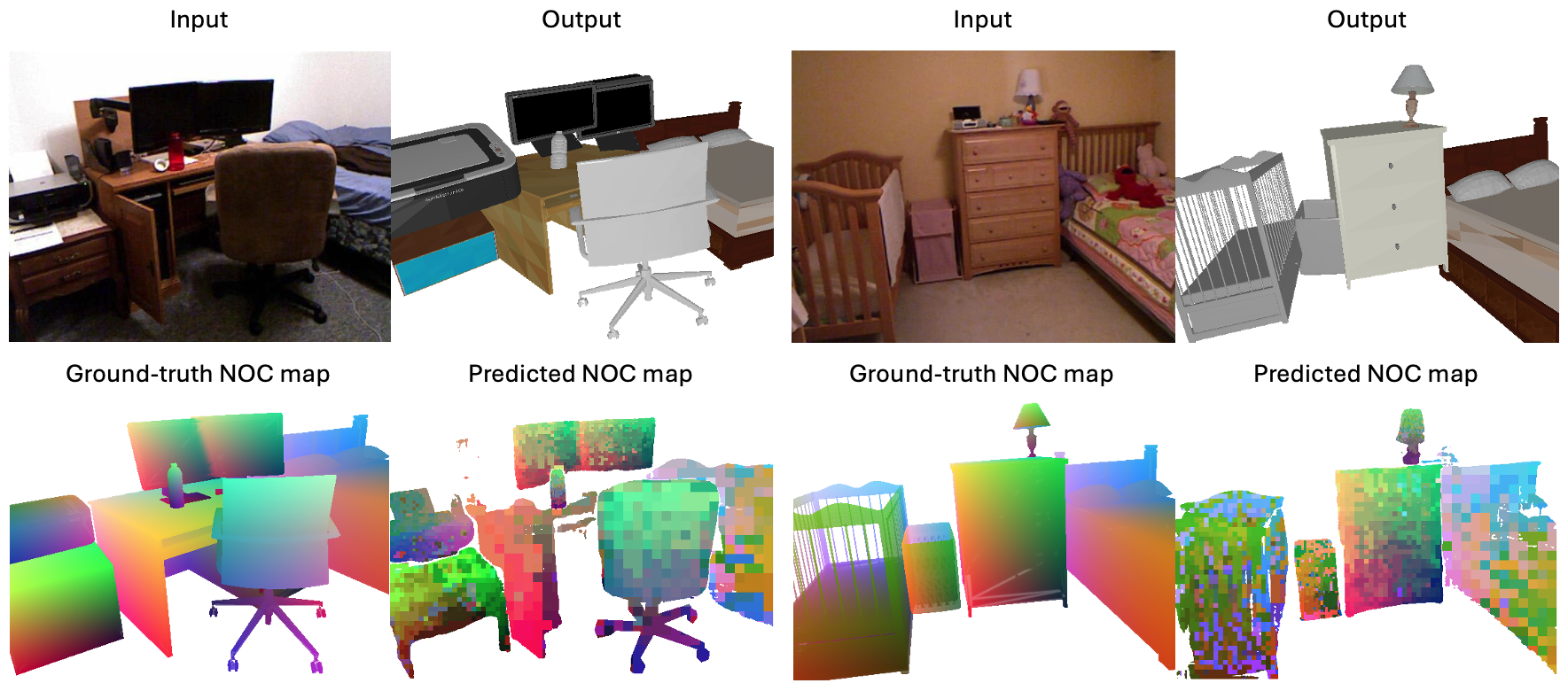 Given an input image and user-selected CAD models, we estimate the 9-DoF pose of each model by aligning it to the target object using the Normalized Object Coordinate (NOC) space, without requiring scene-level pose annotations.
Despite being trained on only 9 classes, our method generalizes well to unseen categories in real images.
Given an input image and user-selected CAD models, we estimate the 9-DoF pose of each model by aligning it to the target object using the Normalized Object Coordinate (NOC) space, without requiring scene-level pose annotations.
Despite being trained on only 9 classes, our method generalizes well to unseen categories in real images.Abstract
Proposed Solution
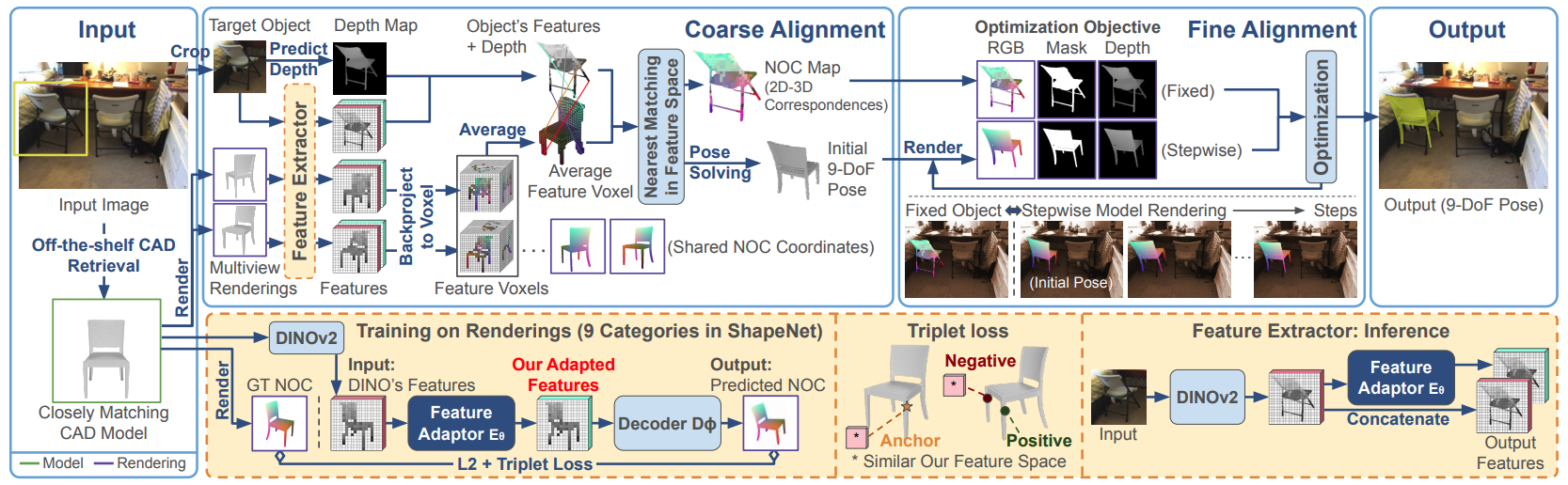 We propose a technique to enhance foundation features and integrate them into a 3D alignment pipeline with a coarse-to-fine estimation scheme.
(1) A coarse 9-DoF pose is estimated using a geometry-aware feature space derived from DINOv2, which is more robust to object symmetries.
(2) The pose is refined through dense alignment optimization in a texture-invariant space (NOC), using a new NOC estimator that generalizes better than prior work.
We propose a technique to enhance foundation features and integrate them into a 3D alignment pipeline with a coarse-to-fine estimation scheme.
(1) A coarse 9-DoF pose is estimated using a geometry-aware feature space derived from DINOv2, which is more robust to object symmetries.
(2) The pose is refined through dense alignment optimization in a texture-invariant space (NOC), using a new NOC estimator that generalizes better than prior work.
Coarse Pose Estimation
Fine Pose Estimation
Alignmet Results
 We evaluate our method on ScanNet and outperform weakly supervised baselines. Additionally, we introduce SUN2CAD dataset, an inexact 9-DoF test set with 20 unseen categories,
where our approach surpasses both the supervised SOTA (SPARC) and weakly supervised baselines, achieving state-of-the-art generalization by a large margin.
We evaluate our method on ScanNet and outperform weakly supervised baselines. Additionally, we introduce SUN2CAD dataset, an inexact 9-DoF test set with 20 unseen categories,
where our approach surpasses both the supervised SOTA (SPARC) and weakly supervised baselines, achieving state-of-the-art generalization by a large margin.
BibTex
@inproceedings{Arsomngern2025ZeroCAD,
author = {Arsomngern, Pattaramanee and Khwanmuang, Sasikarn and Nie{\ss}ner, Matthias and Suwajanakorn, Supasorn},
title = {Zero-shot Inexact CAD Model Alignment from a Single Image},
booktitle = {International Conference on Computer Vision},
year = {2025},
}